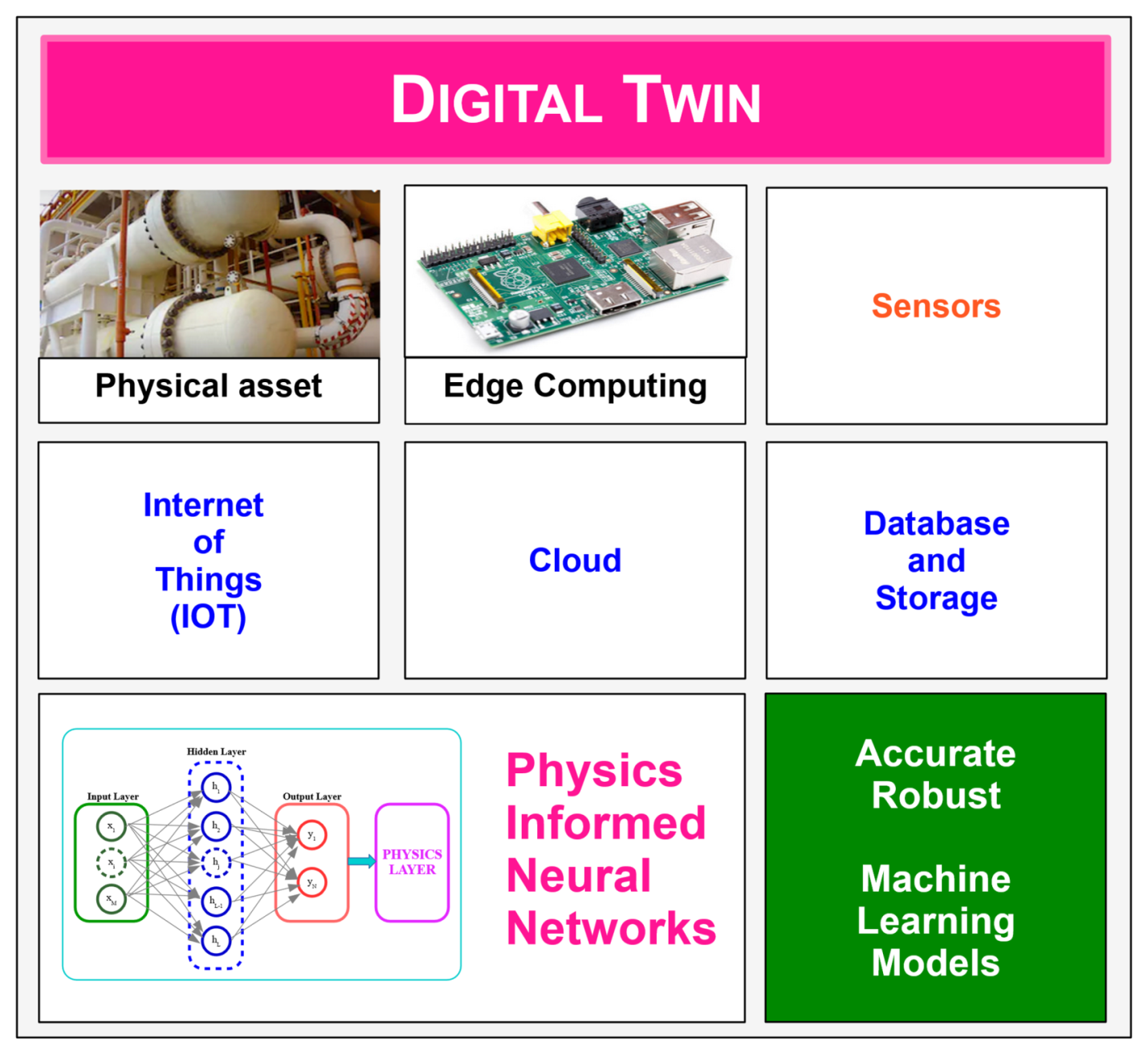
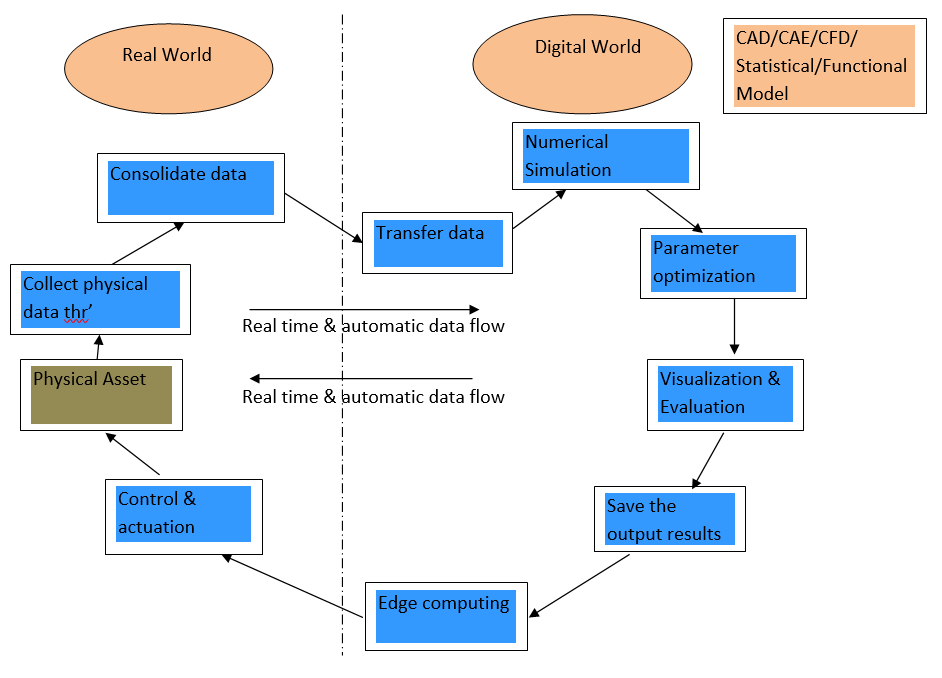
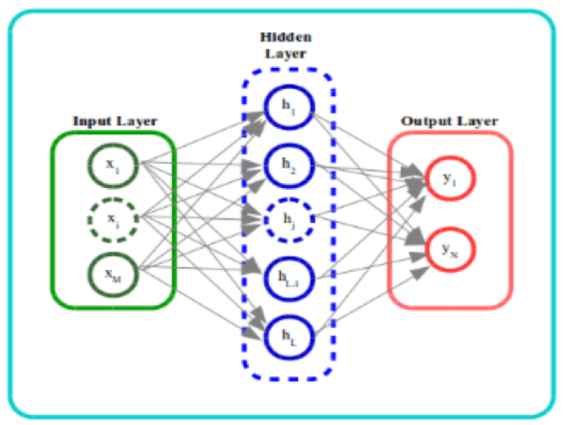
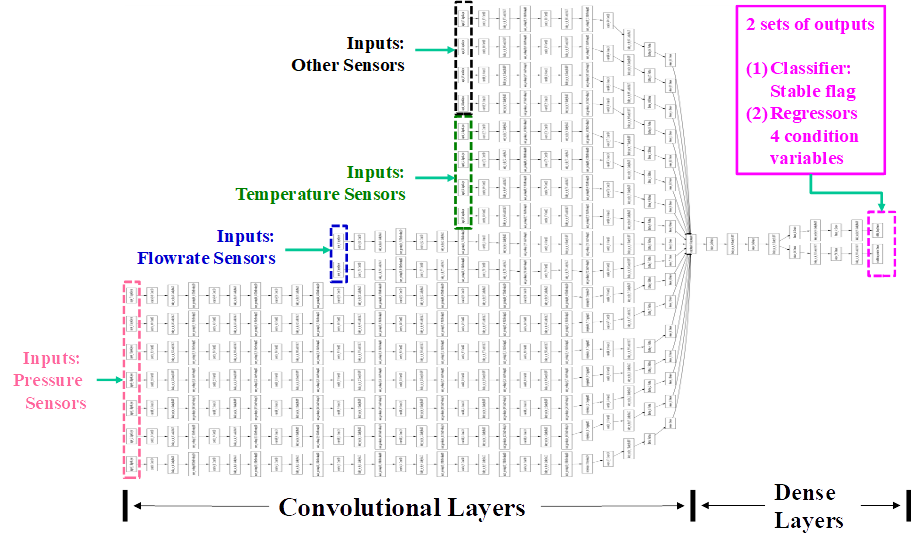
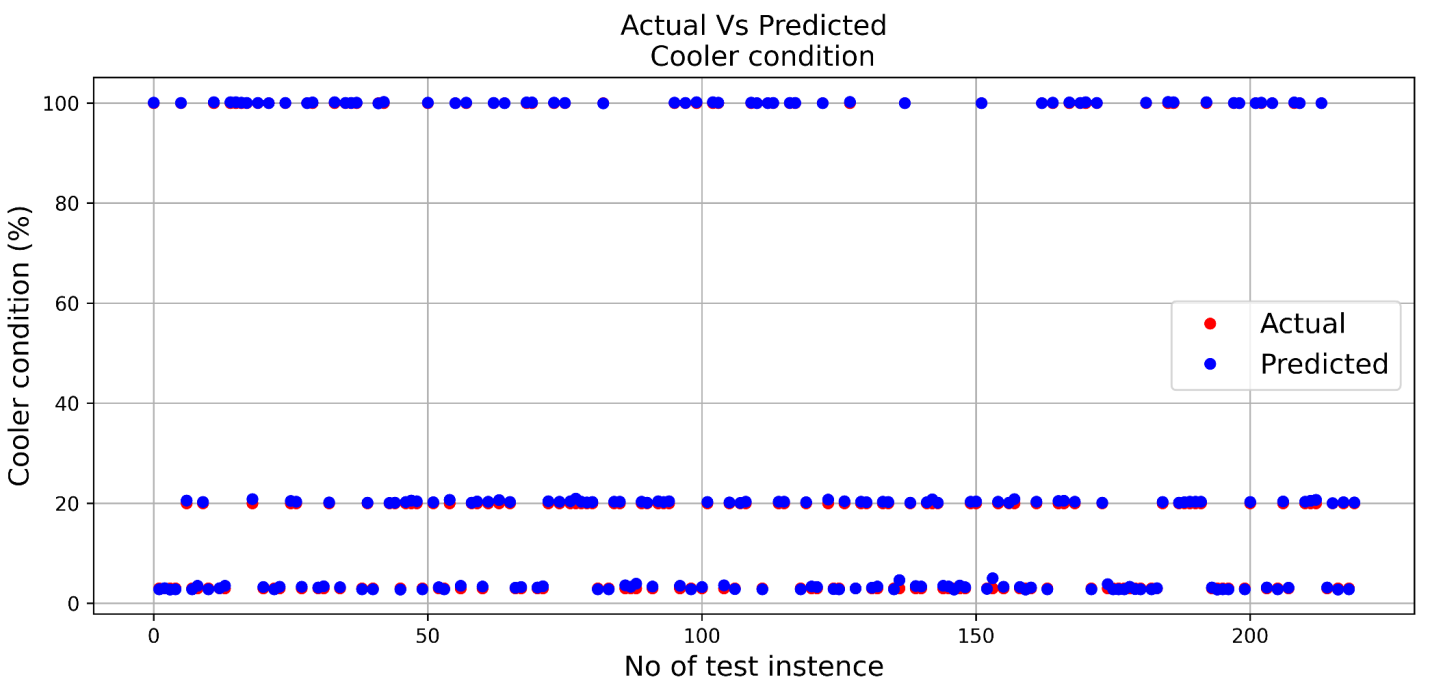
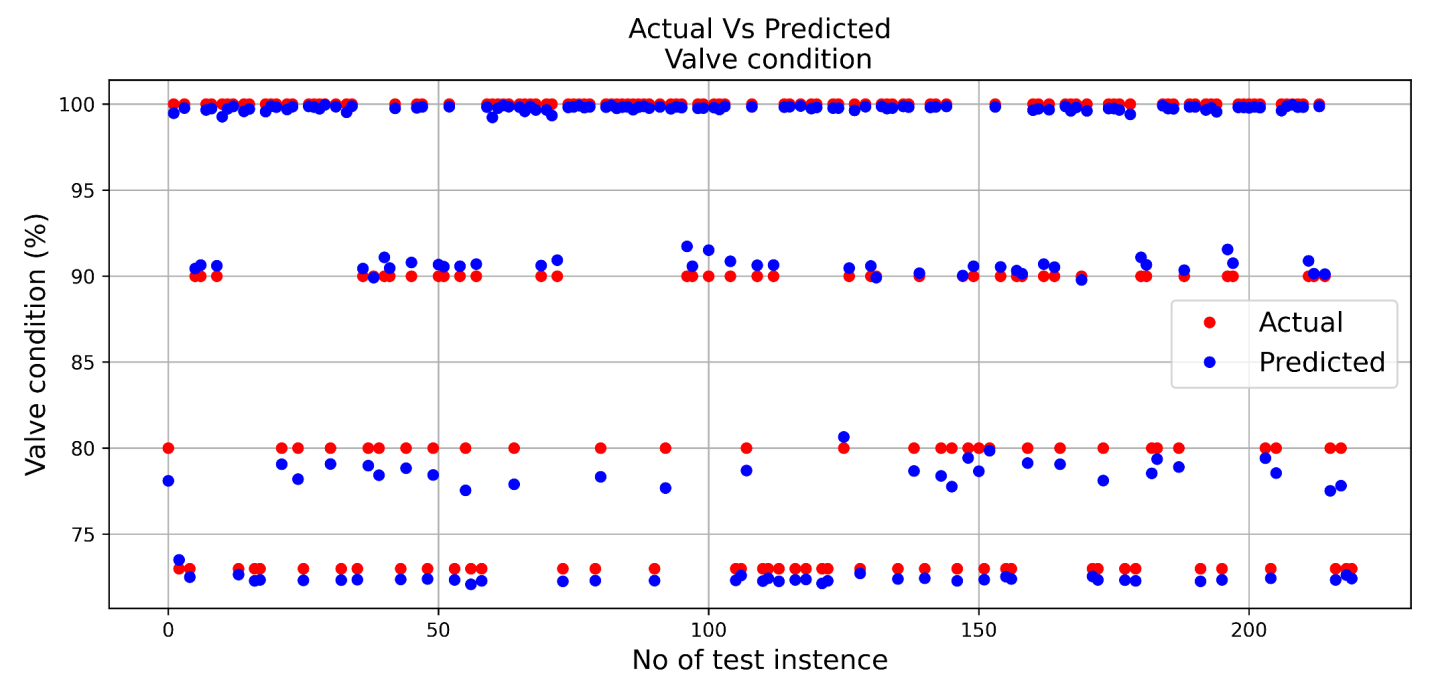
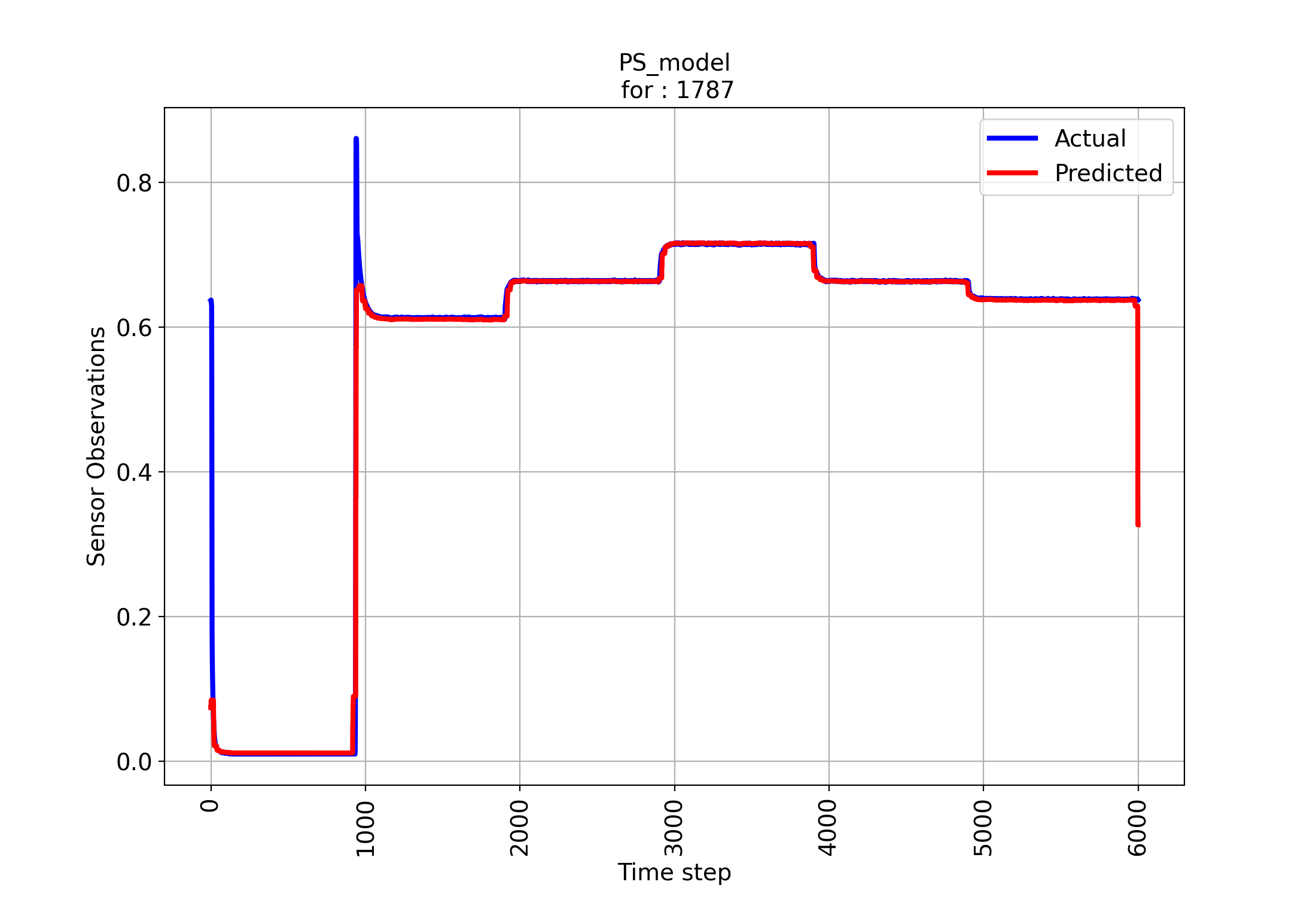
Tasks Performed by Digital Twin
Reduce or eliminate warranty claims: Digital Twin substantially reduce or eliminate warranty claims on the system by minimizing or eliminating the untimely failure of the system. This saves tremendous cost for the organizations.
Predictive maintenance: Digital Twin collects real-time data which can be used as an input to a predesigned condition monitoring system. This gives an early indication of any possible future anomalies. Hence, it is possible to accurately predict the failures, early fault detection, time to failure prediction, we can take timely action to prevent the system downtime, with accurate and just in time maintenance called predictive maintenance. Predictive maintenance or condition based maintenance is performing the maintenance when warranted or based on the actual condition of the system with the degraded state of the components/system, hence prevents unexpected failures, saves lot of time, money, resources and ensures optimum use of the spares or components.
Remaining useful life estimation (RUL): Digital Twin helps in predicting the RUL by analyzing the time series data of sensors. The accurate estimation of remaining useful life (RUL) is critical to the prognostics and health management (PHM) of the system and proactive asset management, this will help reduce the downtime, plan the future production processes, plan the maintenance, spares or inventories, optimum use of the product for its life, amongst many advantages.
Prevent downtime & Avoid catastrophic failures in the field: Real-time data analysis, early detection of anomalies, fault diagnosis (signaling excessive loads/bad operating ranges) and subsequent predictive maintenance will substantially reduce the downtime of a system or any sudden failure in the field. In other words, Digital Twin can be used for condition monitoring and anomaly detection (simulate the health conditions of physical twin): At-a-glance, the information is available to the users via dashboards (mobile/tablet + desktop/browser platforms). Preventing catastrophic failures will help organizations in saving money and ensuring quality, branding, serviceability & reputation (increased safety & reliability of the physical twin).
Product / Process optimization: Digital twin can support production planning and control to optimize the production processes and workflows. Digital Twin offers many benefits to the organizations for improvement in production and logistics processes leading to cost savings and higher flexibility. (Predict the performance & optimize the performance of the physical twin)
Enhanced customer experience, service & branding: Reducing downtime and catastrophic failures of the system in the field result in huge savings; also real time data and analytics will significantly enhance the customer experience and the organization's reputation.
Simulations for deeper insights and what-if studies: Data collected by a digital twin can also be used to conduct any multi-physics simulations for deeper insights and what-if studies, so very helpful in design, analysis and verification/validation of new or existing product/process; Digital Twin could also be used for visualization and in dealing with complex or remote assets.
Real-time data and analytics for future product / process innovations: Real-time operational data of any system/product will be different from the data collected in an experiment. Digital Twin collects real-time data and analyses the data for any inferences or insights. This understanding will greatly help the designers for future developments in the product or process.
Simulations for training purposes: Digital twin can support production planning and control to optimize the production processes and workflows. Digital Twin offers many benefits to the organizations for improvement in production and logistics processes leading to cost savings and higher flexibility. (Predict the performance & optimize the performance of the physical twin)
Product / Process optimization: Data collected from multi-physics simulations can in turn be used to train the Digital Twin.